



Einführung in Predictive Analytics: So setzen Sie auf ihre bestehende IT-Landschaft auf um Mehrwerte zu generieren
Advanced Analytics geht einen Schritt weiter als traditionelle BI. Dabei sind wissenschaftliche Methoden aus der angewandten Mathematik und Statistik im Einsatz. Dazu gehören z. B. Data Mining, Modellierung, Simulation und maschinelles Lernen. Diese werden herangezogen, um die Wahrscheinlichkeit zukünftiger Ereignisse zu bestimmen oder Korrelationen aufzudecken, die durch andere Methoden unentdeckt blieben. Mit Hilfe von Advanced Analytics werden Fragen beantwortet wie
- „Was wird wahrscheinlich als nächstes passieren?“ (Vorhersage)
- „Warum ist das passiert?“ (Korrelation)
- „Was ist das Beste was passieren kann?“ (Optimierung)
Advanced Analytics Methoden sind daher meist vorhersagend (predictive) oder vorschreibend (prescriptive), während traditionelle BI Analysen wie OLAP oder Reporting & Dashboards fast ausschließlich beschreibender Natur (descriptive) sind und Fragen beantworten wie „Was ist passiert?“.
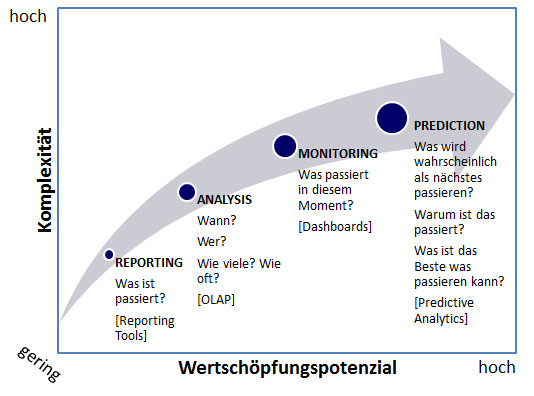
In unserer neuen Serie soll das Thema „Predictive Analytics“ in den Fokus gerückt werden. Nach der Definition des Analystenhauses Forrester® kann zu Predictive Analytics jede Lösung gezählt werden,
- mit deren Hilfe sich aussagekräftige Muster und Abhängigkeiten in Datenbeständen identifizieren lassen,
- und auf diese Weise mögliche zukünftige Ereignisse vorhersagen sowie potenzielle Handlungsmöglichkeiten bewerten lassen.
Damit umfasst Predictive Analytics eine Vielzahl von computergestützten Methoden, die historische oder aktuelle Daten analysieren, um Vorhersagen über die Zukunft zu geben. Frei nach dem Motto „Insight not Hindsight“ handelt es sich bei Predictive Analytics um ein sehr vielschichtiges Thema. Die Anwendung komplexer Methoden auf riesige Datenmengen bringt aber enorme Wertschöpfungspotenziale mit sich.
Sind in die bestehende IT-Landschaft eines Unternehmens bereits CRM- oder BI-Systeme integriert, so können Predictive Analytics-Anwendungen direkt darauf aufbauen. Im Zeitalter von Big Data werden bestehende Infrastrukturen vor neue Herausforderungen gestellt. Die passenden Werkzeuge zu besitzen, um strukturierte und unstrukturierte Daten aus einer Vielzahl unterschiedlicher Datenquellen zusammenzubringen ist zwar auf der einen Seite ein Problem, auf der anderen Seite aber auch eine Chance, neue Erkenntnisse durch die Verknüpfung unterschiedlichster Datentöpfe zu gewinnen.
Mathematisch betrachtet basiert ein Großteil von Predictive Analytics auf der Erfassung von Beziehungen zwischen erklärenden Variablen und den abhängigen Variablen aus vergangenen Ereignissen. Dabei gilt es diese Beziehungen aufzudecken, um prädiktive Scores (Wahrscheinlichkeiten) für Ereignisse zu erstellen. Im Gegensatz zu Forecasts können mit Predictive Analytics Vorhersagen für das Verhalten eines Individuums erstellt und damit ein detaillierterer Grad an Granularität erreicht werden. Zu beachten ist, dass die Genauigkeit und Brauchbarkeit der Vorhersagen stark von der gewählten Methode und der Qualität der zu Grunde liegenden Annahmen abhängen.
Phasen und Methoden von Predictive Analytics: Schritt für Schritt zum Wettbewerbsvorteil
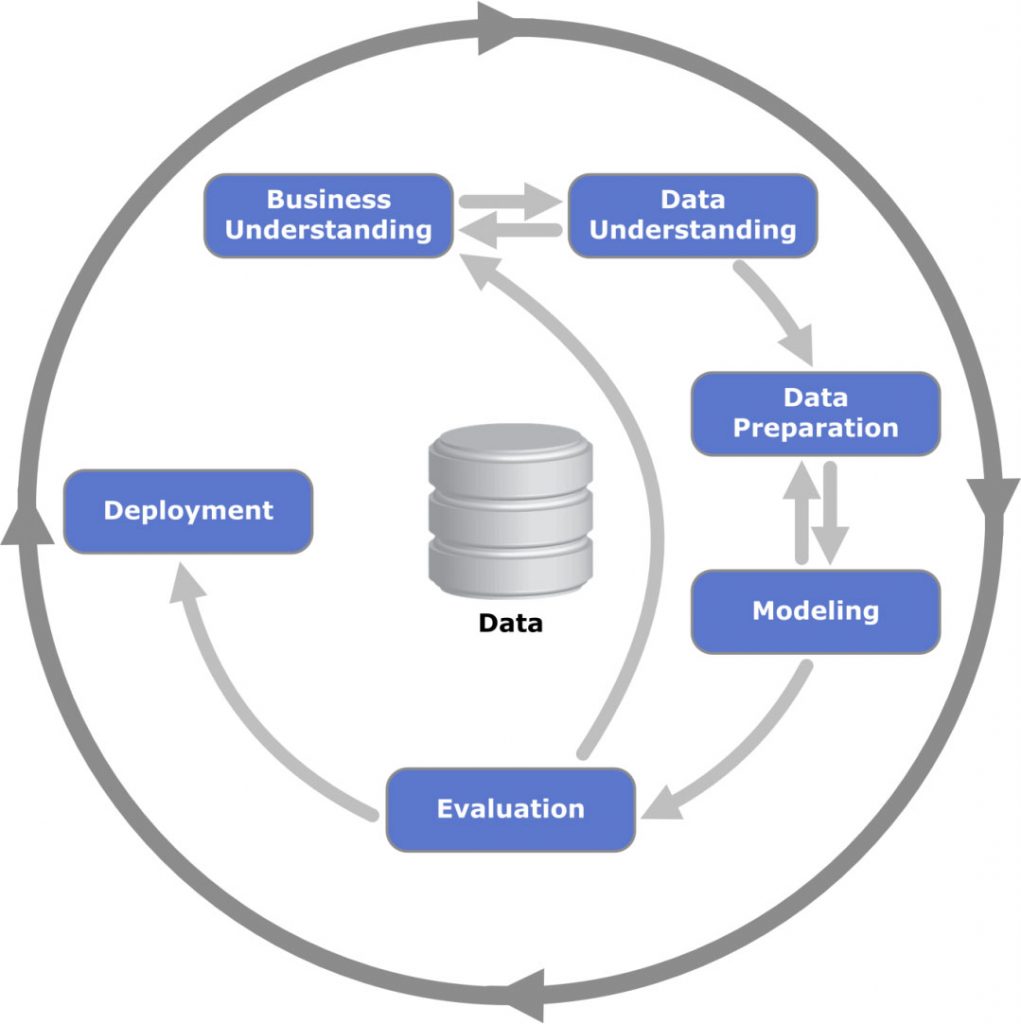
Für die Durchführung von Predictive Analytics Projekten hat sich in den letzten Jahren mit dem „Cross Industry Standard Process for Data Mining“ (kurz: CRISP-DM) ein Standard etabliert, der laut Umfragen in den meisten Projekten im Predictive Analytics und Data Mining Umfeld zum Einsatz kommt. Die Entstehung dieses Ansatzes ist auf das Jahr 1996 zurückzuführen, als ein Konsortium im Bereich Data Mining führender Unternehmen (unter ihnen z. B. Daimler und Teradata) eine Arbeitsgemeinschaft gründete und bis zum Jahr 1999 die erste Version des danach mehrfach optimierten Ansatzes entwickelte.
Der äußere Kreis der Grafik von oben verdeutlicht den zyklischen Charakter von Predictive Analytics. Ein Data Mining Prozess hört nach der Inbetriebnahme nicht auf:
Auch nach der Inbetriebnahme ist es essenziell, die Geltung der getroffenen Annahmen zu überprüfen und gegebenenfalls anzupassen. Die Verantwortlichen sollten sich stets darüber im Klaren sein, auf welchen Annahmen sie ihr Modell aufgebaut haben und unter welchen Voraussetzungen diese nicht mehr zuträfen. Ebenso ist darauf zu achten, dass keine wichtigen Einflussvariablen bei der Modellierung vergessen wurden. Derartige Lessons Learned machen eine kontinuierliche Anpassung der Modelle notwendig.
Das Innere der Grafik zeigt, dass nach CRISP-DM 6 Phasen unterschieden werden, die im Folgenden näher beleuchtet werden sollen.
Business Understanding – Vor der Antwort kommt die Frage
In dieser Phase gilt es die Rahmenbedingungen zu verstehen und die wirtschaftlichen Ziele des Projektes zu klären. Anschließend sind die wirtschaftlichen Fragestellungen in Predictive-Analytics-Problemstellungen zu transferieren. Hierbei handelt es sich um den wahrscheinlich wichtigsten Schritt im Predictive Analytics/ Data Mining Prozess. Ohne gut durchdachte Problemstellungen ist es so gut wie unmöglich die richtigen Daten zu sammeln und die richtigen Algorithmen anzuwenden.
Data Understanding – Den Wald vor lauter Bäumen sehen
In dieser Phase steht die initiale Datensammlung am Anfang. Daraufhin macht man sich mit dem Datenbestand vertraut und macht sich auf die Suche nach Problemen in der Datenqualität.
Data Preparation – Was nicht passt, wird passend gemacht
Hat man in der Phase zuvor einen Überblick über die Rohdaten erlangt, gilt es nun diese Daten in eine Form zu bringen, mit der unsere Predictive-Analytics-Modelle arbeiten können. Neben der Auswahl der benötigten Tabellen, Attribute und Einträge, gehören hierzu auch die Datenbereinigung (Cleansing) und die Transformation der Daten in die benötigten Formate.
Modeling – Viele Wege führen nach Rom
Diese Phase beinhaltet die Anwendung der ausgewählten Modellierungstechniken. Frei nach dem Motto „viele Wege führen nach Rom“ wird es in der Regel eine Vielzahl von Ansätzen für die gleiche Problemstellung geben. In diesem Zusammenhang besteht die Herausforderung, die beste Modellierungsmethode für das vorliegende Predictive-Analytics-Problem zu identifizieren. Da unterschiedliche Modellierungsmethoden unter Umständen andere Anforderungen an die Form der Daten haben, ist es nicht unüblich, die Data Preparation anzupassen, bevor man mit der eigentlichen Modellierung eines Alternativansatzes fortfährt.
Die Vielzahl an Modellen abzuhandeln, die in diesem Rahmen einsatzfähig sind, würde bei Weitem den Rahmen sprengen. Wir möchten hier nur einen kurzen Auszug der riesigen Bandbreite an Modellen widerspiegeln:
- Klassifikationsmethoden
- Entscheidungsbäume
- Künstliche Neuronale Netze
- Bayessche Netze
- Support Vector Maschinen
- Ensemble Modelle
- Regressionsmethoden
- Assoziationsanalysen (z. B . Warenkorbanalysen)
- Zeitreihenanalysen
Alle Techniken vereint eins: Der Ansatz die vorhandenen Daten in Trainingsdaten und Testdaten aufzuteilen (partitionieren). Dem zu Grunde liegt die Annahme, dass die vorhandenen Daten adäquat die Voraussetzungen repräsentieren, die sowohl in der Vergangenheit als auch in der Zukunft vorherrschen. Dabei ist darauf zu achten, dass die Partitionierung zufällig (in einem zuvor definierten Verhältnis z. B. 70% zu 30%) erfolgt, um zu verhindern, dass die Zusammensetzung einer oder beider Gruppen in Teilen einem Muster folgt. Die Trainingsdaten (auch als Lerndaten bezeichnet) werden zu der Erstellung des Modells herangezogen. Durch die Masse an Daten „lernt“ das Modell dazu bzw. „trainiert“ seine Effektivität. Die Testdaten dienen der Evaluierung und schließlich der Auswahl der Modelle (Welches der betrachteten Modelle liefert statistisch die besten Ergebnisse?). Insgesamt stellt die Partitionierung der Daten eine wichtige Voraussetzung dar, um gewährleisten zu können, dass das schließlich ausgewählte Modell akkurate und verlässliche Vorhersagen liefert.
Evaluation – Vertrauen ist gut, Kontrolle ist besser
Auf die Phase der Modellierung folgt die Evaluation. In dieser Phase soll die Frage beantwortet werden, ob das ausgewählte Modell in angemessener Art und Weise die dem Projekt zu Grunde liegenden wirtschaftlichen Fragestellungen beantworten.
Für Klassifikationsmethoden sind oft Wahrheitsmatrizen (auch Konfusionsmatrizen genannt) im Einsatz. Aus ihnen werden Kennzahlen wie Sensitivität, Spezifität, Genauigkeit oder Trefferquote errechnet. Für weitergehende Analysen sind sog. ROC-Kurven (Receiver-Operating-Characteristic-Kurve) und Lift-Charts beliebt.
Deployment – Nicht reden sondern handeln
Hat das Modell auch der Evaluation standgehalten, so gilt es die erlangten Erkenntnisse in die Entscheidungsprozesse des Unternehmens zu integrieren. Das Ausmaß dieser Phase kann dabei sehr unterschiedlich sein und von der Erstellung eines einfachen Reports bis hin zur automatisierten Umsetzung der bewerteten Handlungsoptionen (Prescriptive Analytics) gehen.
Im nächsten Teil unserer Serie werden wir unseren Fokus auf Use Cases, also dem Einsatz von Predictive Analytics in der Praxis verlagern.
Analytics Use Cases in allen denkbaren Bereichen
Analytics Use Cases lassen sich entlang der gesamten Wertschöpfungskette finden. Um einen groben Überblick zu geben, orientieren wir uns an der Wertkette:
Einkauf
Im Bereich des Einkaufs können, z. B. Absatz- oder Preisprognosen dafür sorgen, dass bestmögliche Einkaufsstrategien entwickelt werden und kostspielige Über- und Unterbestände vermieden werden. Dies ist vor allem im Falle von stark schwankenden Rohstoffpreisen und hohen Einkaufsvolumina zu empfehlen.
Produktion
Als Beispiele für Analytics Use Cases in der Produktion wollen wir Losgrößenoptimierung, Predictive Maintenance und Personaleinsatzplanung nennen. Hierbei geht es darum, Kapazitäten besser auszulasten, Ausschuss zu verringern bzw. mögliche Produktionsausfälle frühzeitig zur prognostizieren. Auf der Grundlage von Analysetechniken und der Visualisierung der Ergebnisse (z. B. in Form von Dashboards) können Mitarbeiter schnellere und besser fundierte Entscheidungen treffen.
Distribution
Analytics in der Distribution besteht hauptsächlich aus der Optimierung von Logistikprozessen, vor allem von Transport- und Lagerprozessen.
Marketing/Vertrieb
Customer Churn, Dynamic Pricing, Customer Value, Up-&Cross-Selling u. v. m. – Die Liste von Analytics Use Cases in den Bereichen Marketing und Vertrieb ist lang. Die Use Cases haben das Ziel das gesammelte Wissen über die Kunden zu bündeln und gezielt nutzbar zu machen. Gelingt dadurch eine individuellere Kundenansprache und eine Verbesserung der Kundenerfahrung, stärkt dies die Kundenbindung und damit den Unternehmenserfolg.
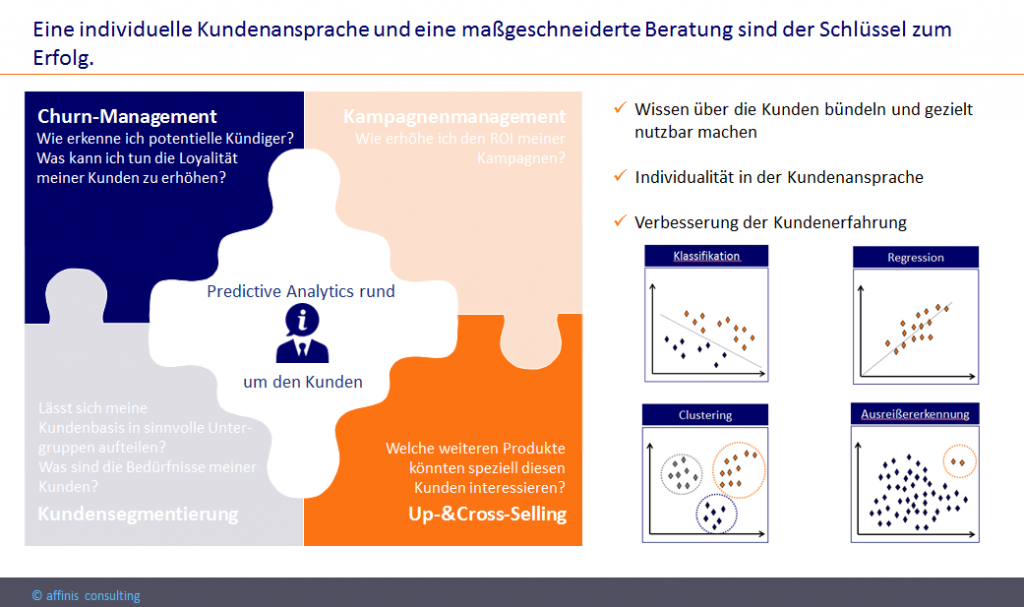
(Kunden-) Service
Fortgeschrittene Analysen können auch helfen individualisierte Kundeninteraktion, Tarife und Service-Level sowie optimierte Antwortzeiten zu bewirken.
Besseres Kundenverständnis durch Predictive Analytics: Gezielte Kündigungsprävention durch individuelle Kundenansprache
Am Beispiel der Kundenabwanderungs-Prävention, dem sog. Churn-Management wollen wir uns folgendes im Detail ansehen:
- Welche Motivation/Leitfragen stecken hinter diesem Use Case?
- Welche Methoden kommen zur Anwendung?
- In welcher Form stiftet dieser Use Case Nutzen?
Motivation/Leitfragen
Neukundengewinnung ist um ein vielfaches teurer als Kundenbindung.
- Wie erkenne ich potentielle Kündiger?
- Was kann ich tun die Loyalität meiner Kunden zu erhöhen?
- Was biete ich einem Kunden an, damit er seine Kündigung zurückzieht?
Methodik
- Einsatz von Klassifikations- und Regressionsmethoden
- Mit Hilfe meiner beschrifteten, historischen Daten trainiere und teste ich den Algorithmus
- Erst wenn der Algorithmus eine zufriedenstellende Güte aufweist, verwende ich ihn dafür die Kündigungsneigung meiner aktiven Kunden individuell vorherzusagen
- Regelmäßige Aktualisierung (Closed Loop Ansatz)
- Darüber hinaus können Kundenwertberechnungen helfen die Kunden, die auf Grund eines hohen Werts für das Unternehmen unbedingt gehalten werden sollten, zu identifizieren
Nutzen von Predictive Analytics
- Durch Kündigungsprävention Kundenabwanderung (von profitablen Kunden) vermeiden
- Rückgewinnung von Kunden die bereits gekündigt haben
- Einen neuen Kunden gewinnen ist für Unternehmen 5-10 mal so teuer, als einen bestehenden Kunden zu halten
Eine individuelle Kundenansprache ist die Chance sich von der Konkurrenz abzuheben und Wettbewerbsvorteile zu generieren. Ihre Kunden werden es Ihnen danken.
Quellen
Noch mehr spannende Beiträge

Power BI Log.Insights – Effektives Power BI Monitoring zur optimalen Verwaltung von Systemen
Mit Power BI Log.Insights erhalten Unternehmen umfangreiche Einsichten in ihre Power…

Power BI Log.Insights als kritischer Faktor für Unternehmen am Beispiel IDV
Wie lassen sich die regulatorischen Anforderungen der IDV in Self Service-Szenarien mit Microsoft…

{kind=link}
Regulatorische Anforderungen in Self Service-Szenarien und der IDV mit Microsoft Power BI meistern
Wie lassen sich die regulatorischen Anforderungen der IDV in Self Service-Szenarien mit Microsoft…