
Künstliche Intelligenz und Machine Learning für eine optimale Customer Experience bei Versicherungen
In diesem Blogbeitrag zeigen wir Ihnen, wie Versicherungsunternehmen mit Künstlicher Intelligenz herausfinden können, was ihre Kunden brauchen und möchten. Dazu wurde ein Produktempfehlungssystem für Versicherungsprodukte auf Basis statistischer Lookalikes entwickelt.
Was ist Machine Learning?
Bevor wir darüber berichten, wie Künstliche Intelligenz die Customer Experience einer weltweit operierenden Versicherung optimieren konnte, möchten wir erst einmal kurz die Basis für den folgenden Blogbeitrag definieren. Was versteht man eigentlich genau unter Machine Learning? Dazu sei gesagt, dass Machine Learning sich im Ansatz von klassischer Programmierung unterscheidet.
Machine Learning ist ein Ansatz, um das Ziel der künstlichen Intelligenz zu erreichen. Es eignet sich besonders gut für das Lösen spezieller Probleme, bei denen es viele enge Fallunterscheidungen gibt, die von einem Programmierer nicht manuell umgesetzt werden können.
Beim klassischen Programmieren erhält ein Programmierer Anforderungen, die die Realität abbilden sollen und definiert daraufhin ein Modell, welches die Daten entsprechend verarbeitet. Hierbei wird der Input immer genau so verarbeitet, wie es vom Programmierer definiert wurde. Das bedeutet auch, dass der Programmierer alle Möglichkeiten bedenken und formulieren muss. Bei Machine Learning hingegen ist das anders. Der Programmierer stellt hierbei den Input und den dazu gewünschten oder real vorkommenden Output bereit. Anhand dieser validierten Paare erlernt der Algorithmus die Beziehung zwischen Input und Output, auch Supervised Machine Learning genannt. Dadurch wird ein komplexes Modell erzeugt, mit dem die Kundenbedürfnisse prognostiziert werden können.
Machine Learning: nicht eine Lösung für jedes Problem
Es ist jedoch anzumerken, dass nicht jedes Problem mit Machine Learning gelöst werden kann bzw. auch sollte. Einfache Probleme sollten eher mit Hilfe klassischer Programmierung gelöst werden. Stellen wir uns für ein einfaches Problem einen Roboter vor, dem beigebracht werden soll, über eine Fußgängerampel zu gehen: bei Rot soll er stehen bleiben, bei Grün soll er gehen. Bei einem Input der entweder „Grün“ oder „Rot“ ist, wie in dieser Situation, ist die klassische Programmierung eher geeignet als Machine Learning. Hier reden wir von einer einfachen Beziehung.
Stellen wir uns jetzt aber vor, dass der Roboter lernen soll zwischen Bildern von Äpfeln und Birnen zu unterscheiden, liegt eine deutlich komplexere Situation vor. Anhand verschiedener Merkmale (z.B. Form, Farbe, etc.) muss erkannt werden, um welches Obst es sich handelt. Für uns eine leichte Aufgabe, aber auch nur, weil wir von klein auf gelernt haben, diese Dinge anhand verschiedener Faktoren zu unterscheiden. Für solche komplexeren Herausforderungen, bei dem das Lernen von verschiedensten Merkmalen eine Rolle spielt, sollte daher Machine Learning angewendet werden.
Warum Machine Learning bei Versicherungen und was ist das Ziel?
Kommen wir nun aber zu unserem Case: Ein weltweit führendes Versicherungsunternehmen wollte ihre Kunden mit individuellen Inhalten ansprechen, um die Kundenbindung und Kundenzufriedenheit zu erhöhen. Um dieses Ziel zu erreichen, musste eine Methode entwickelt werden, mit der sich die Bedürfnisse der Kunden bestimmen lassen – was bei 12 Mio. Kunden natürlich manuell nicht so einfach möglich ist. Somit war Machine Learning die einzige Möglichkeit, dieser komplexen Herausforderung zu begegnen.
Auf Basis von Bestandsdaten und unter Verwendung von maschinellem Lernen können demnach Prognosen für die Zukunft abgeleitet werden. Fragen wie „welchen Kunden biete ich welches Produkt zu welchem Zeitpunkt an“ können mit solchen Prognosen beantwortet werden. Diese werden dann genutzt, um Kunden personalisierte Inhalte und Angebote zukommen zu lassen und um letztendlich die richtigen Empfehlungen für jeden Einzelnen auszusprechen.
Solche so genannten Lookalike Prinzipien werden auch von großen Technologiekonzernen wie Facebook für die eigenen Marketingaktivitäten genutzt.
Was versteht man beim Machine Learning unter Lookalikes?
Mithilfe von Supervised Machine Learning wird ermittelt, welche Faktoren dazu führen, dass ein Kunde einen Vertrag in der zu untersuchenden Produktklasse abgeschlossen hat. Anhand dieser Faktoren wird ein Modell erzeugt, mit dem ein Affinitätswert zu dieser Produktklasse für alle Kunden errechnet wird. Jeder Kunde hat verschiedene Merkmale, die ihn ausmachen und verschiedene Verträge, die er abgeschlossen hat. Bei einer Lookalike Modellierung werden Merkmale ermittelt, die Kunden, die einen bestimmten Vertrag abgeschlossen haben, gemeinsam haben. Das Modell lässt anhand von gemeinsamen Merkmalen letztendlich auf eine Produktaffinität schließen. Diese nennt man statistische Zwillinge, oder auch Lookalikes.
Herstellung von Algorithmen mit Trainingsdaten beim Supervised Machine Learning
„Machine Learning Ergebnisse können nur so qualitativ sein, wie die Qualität und Menge an Daten, die bearbeitet werden“ – Tobias Jenner.
Beim Supervised ML stehen die Trainingsdaten im Vordergrund, da die Herstellung der Modelle auf den Training- und Testdaten Sets basieren. Trainingsdaten müssen so allgemein wie möglich und so genau wie nötig sein. Der Ablauf wird in der nachfolgenden Abbildung grafisch visualisiert:
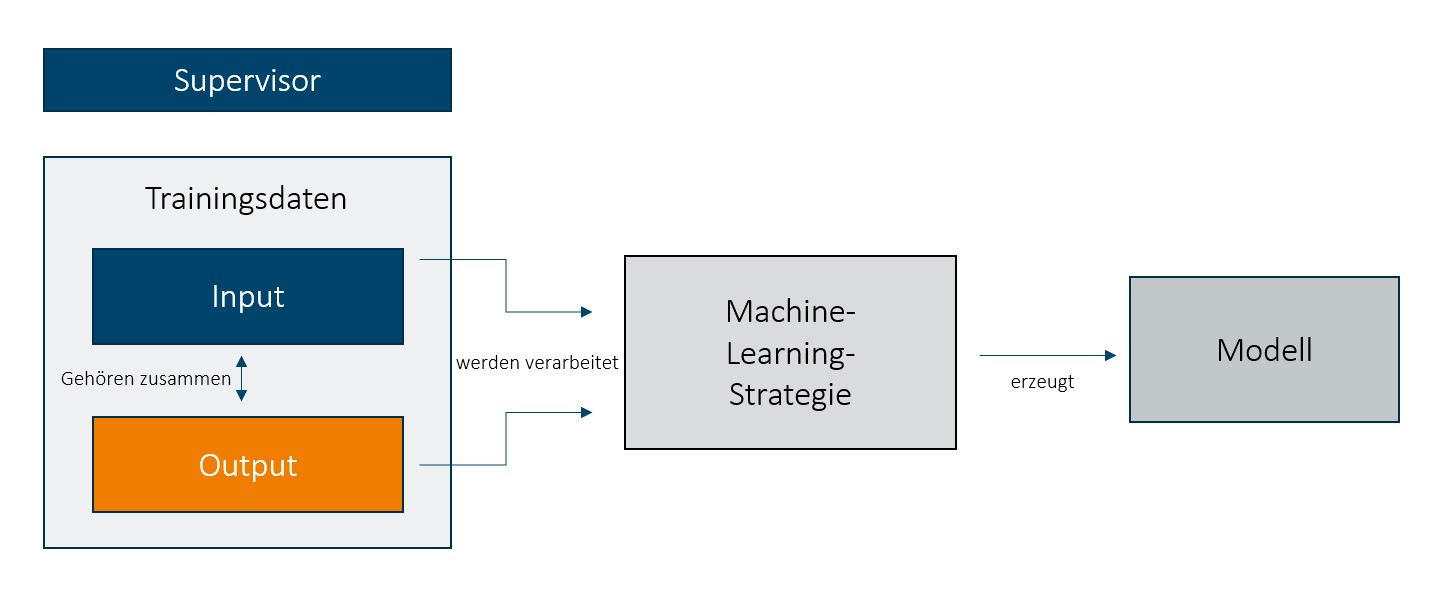
In unserem Fall ist der Input „der Kunde“ und der Output „der Kunden hat einen Vertrag für folgendes Produkt abgeschlossen“. Dieses entspricht der Realität und ist durch eine hohe Menge an Daten validiert.
Die Input und Output Daten werden anschließend mit Machine Learning bearbeitet und ergeben ein Modell, welches den Kundenbedarf prognostizieren kann. Das Ziel ist es, einen „Good Fit“ bzw. ein robustes Modell daraus zu erhalten (im Gegenteil zu einem Underfitted/Overfitted Model).
Unter einem „Good Fit Model“ versteht man ein Modell, welches generell anwendbare Beziehungen erlernt hat – ohne nur die Trainingsdaten „auswendig“ gelernt zu haben.
Wie wurden die Ergebnisse genutzt und was kam bei der Nutzung von diesem Algorithmus heraus?
Die Ergebnisse wurden genutzt, um ein allgemeines Produkt-Empfehlungssystem aufzubauen – auch „Next Best Product“ System genannt. Dieses Empfehlungssystem zeigt, welche Bestandskunden die höchste Affinität für ein weiteres Versicherungsprodukt haben. Darauf basierend wird der Inhalt für den einzelnen Kunden individuell angepasst. Dies wird auch als Data Driven Marketing bezeichnet.
Die Ergebnisse werden bei Bestandskunden des Versicherungsunternehmen bei der Contentauswahl auf folgenden Kanälen genutzt:
- Telefonie im Service2Sales: beispielsweise wird beim Anruf eines Kunden, der seine Adresse ändern möchte, auf das Next Best Product hingewiesen.
- Online-Portal: es wird ein Banner mit personalisierten Anzeigen gezeigt, die genau auf die Bedürfnisse des Kunden angepasst sind, anstatt nicht relevanter Anzeigen.
- Persönlicher Vertrieb: das Next Best Product wird als Ansprechanlass beim jährlichen Gespräch genutzt.
- Brief und E-Mail: vertriebliche Aktionen werden auf die Produktaffinität des Kunden ausgerichtet und die Newsletter werden zum Teil automatisiert für den Kunden individualisiert.
Fazit zu Machine Learning bei Versicherungen
Machine Learning zeigt großes Potential bei der Entwicklung von Produktempfehlungen und somit der Verbesserung der Customer Experience von Unternehmen.
Sie möchten erfahren, was Machine Learning für Ihr Unternehmen tun kann? Nehmen sie Kontakt mit uns auf und finden sie mit uns die passende Lösung für Ihre komplexen Probleme.
Noch mehr spannende Beiträge

Die Informationsbedarfsanalyse: Strukturierte Anforderungserhebung zur Entscheidungsoptimierung
Strukturierter und effizienter zur erfolgsversprechenden Anforderungsdefinition – die…

Chancen für Versicherungen: Mit der Digitalen Rentenübersicht zu individuellen Mehrwerten
Die Digitale Rentenübersicht stellt Versicherer vor Herausforderungen. Bei der Umsetzung der…

Power BI Log.Insights – Effektives Power BI Monitoring
Mit Power BI Log.Insights erhalten Unternehmen umfangreiche Einsichten in ihre Power…